

Case in point is a recent set of blogs, published by a leading DevOps consultant, after working with a major client to build the UK’s largest IoT platform. The client also standardized on the Wavefront analytics service to assure the cloud platform’s operational performance as it grows functionality and usage:
“To get right to the point, Wavefront is amazing, and you need it. You need it because it will let you see right into the heart of your system, however big and complicated that might be. You need it because you want to alert off meaningful telemetry gathered from every corner of your estate, not off a shell script that exits 1, 2, or 3. You need it because, well, scaling Graphite.
In a nutshell, Wavefront is a service into which you shovel time-series data: collectd, statsd, JMX, Ruby’s logger, anything. Then, you can perform arbitrary mathematical operations on any number of those series. It scales seamlessly, it works all the time, the support is great, it’s feature-complete, and it’s well documented. It’s everything you always want, but never get.”
In particular, the three-part blog series details how to extend Wavefront analytics to Solaris and SmartOS environments – capable of enabling cloud computing infrastructure within enterprise and cloud providers:
“My current client uses Wavefront in production on an Ubuntu estate, but I have an all-SunOS (Solaris and SmartOS) lab, and I thought it would be interesting to instrument that. I can imagine lots of exciting possibilities wiring DTrace, kstats, and all manner of other stuff in, and I’m planning to write up my progress as I go.”
You can find links to the complete blog posts here:
Wavefront and Solaris, Part 01: The Proxy – covers how to get a Wavefront proxy running on a Solaris machine.
Wavefront and Solaris, Part 02: Collecting Metrics, or Adventures in Kstats – covers alternatives to pulling metrics out of Solaris and into the Wavefront proxy.
Wavefront and Solaris, Part 03: Dtrace – covers how to convert the output of a simple Dtrace script into a Wavefront chart.
As the posts demonstrate, the typical road to software integration is not perfectly paved; there can be some pot holes. Similarly, there are often multiple approaches to ultimately making a system work–some are better than others. The blog posts detail this journey, eventually converging on Dtrace as the metrics collector for this use case to integrate with Wavefront. Dtrace is a dynamic tracing framework providing operational metrics to help tune the kernel and applications. It was originally designed for Solaris by Sun Microsystems, but has since been ported to FreeBSD and NetBSD Unix, as well as in Max OS X 10.5 and Linux.
“If you want to get numbers which show you what’s happening in a Solaris system, then DTrace is very much your friend. There are infinite possibilities in wiring DTrace’s deep introspections into Wavefront.”
The post reaffirms a consistent gripe we hear about Graphite’s lack of resilience at scale:
“Back in the dark days of maintaining a Graphite ‘cluster’ (I use quotes because Graphite clusters don’t really scale and aren’t really resilient, the two factors which I think define clustering) perhaps my biggest problem was developers adding new metrics, or slightly changing metric paths, and hundreds of new whisper files appearing, and filling the disks. Again. With Wavefront that’s not an issue. So it effectively free to quickly spin up a DTrace script and shove its output into the proxy with second resolution and a unique metric path.”
Finally, see the post’s summary of the correlative value of Wavefront to ingest and render event tags along with charted metric data:
“I particularly like Wavefront’s ability to apply any number of key=value tags to a point. This lets you build up multi-dimensional data. Tags are fully integrated in the query language, so you can use them for all manner of selection and filtering. They’re also handy markers, giving clues that might be useful in further investigation.
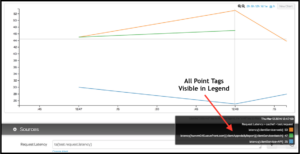 At my current client’s site, we have a Puppet reporter which, at the end of each run, pumps all the statistics for that run (times, change and error counts etc.) into Wavefront. It tags all these points with the release of the Puppet code, so if we see, say, a spike in run time, or something starts making flappy changes, it’s easy to know which Puppet release caused the problem. We can also easily find any machines which aren’t on the same release but should be.”
At my current client’s site, we have a Puppet reporter which, at the end of each run, pumps all the statistics for that run (times, change and error counts etc.) into Wavefront. It tags all these points with the release of the Puppet code, so if we see, say, a spike in run time, or something starts making flappy changes, it’s easy to know which Puppet release caused the problem. We can also easily find any machines which aren’t on the same release but should be.”
You can easily find all the code snippets the author developed in his journey within the blog series. But if you’d like to contact the author for more clarification, give us a shout at info@wavefront.com, and we’ll be happy to broker an introduction.
Ready to get your hands dirty with Wavefront? Get started with Wavefront & request your free trial now.
The post A User’s Insights for Extending Wavefront to Solaris appeared first on Wavefront by VMware.





















